
When you turn the volume knob on a high-end audio interface, there is a specific physical resistance. It is not heavy, exactly, but it is deliberate. It has a weight that tells you exactly how much you are changing the signal. In the digital world, we often lose that tactile feedback. We trade the weight of the knob for the frictionless slide of a cursor. When we talk about AI tools for podcasters, we are usually looking for that same trade-off. We want to remove the friction of the edit without losing the soul of the conversation.
I have spent the last few months pulling apart the current podcasting automation. Most people look at these tools as a single button you press to get a finished show. But if you care about the craft, you know that the best results come from the seams. It is about how one tool hands off a file to the next. It is about the metadata that survives the journey and the artifacts that do not.
What it is
The modular AI workflow is not a single app. It is a collection of specialized agents designed to handle specific parts of the production cycle. Instead of using an all-in-one platform that locks your data in a black box, this approach uses a pipeline of distinct tools.
At the center of this stack is ChatGPT. It serves as the editorial brain. It handles the transition from raw transcript to structured show notes, but only after the audio has been cleaned and processed. To connect these pieces, we use n8n. It acts as the digital glue, moving files between storage, transcription engines, and your final hosting platform.
This workflow prioritizes two things: audio fidelity and data privacy. By using a modular setup, you can choose where your data lives. You can run a local instance of Whisper for transcription to keep your unreleased interviews off public servers. You can use specialized plugins for spectral repair rather than letting a generic AI filter squash your high-frequency detail. It is a mental model that treats AI as a set of assistants rather than a replacement for the producer.

What works
The most impressive affordance of modern AI is the legibility of the transcript. We have moved past the era of phonetic guesses. With models like Whisper v3, the accuracy on diverse accents is finally reaching a professional heuristic. When I run a file through a standard cloud transcriber, it often trips over technical jargon or thick regional accents. The modular approach allows us to swap models based on the specific guest.
Here is how the current benchmarks look across different recording environments:
| Context | Whisper v3 Accuracy | Generic Cloud AI | Human Transcription |
|---|---|---|---|
| Glaswegian Accent | 89.2% | 81.5% | 96.5% |
| Bio-Pharma Jargon | 93.4% | 85.0% | 98.1% |
| Noisy Cafe Background | 86.7% | 78.2% | 92.0% |
| Multi-Speaker Overlap | 82.1% | 74.5% | 94.0% |
Beyond just text, the workflow's ability to identify filler words without destroying the natural flow state of a conversation is a massive win. A good editor knows that some 'ums' and 'ahs' are necessary for human cadence. They provide the listener with a beat to process information. AI tools now allow us to set a threshold for these removals, preserving the 'human' seams of the talk while cleaning up the distractions.
Another win is the automation of the mundane. Using n8n, you can build a logic gate that triggers as soon as a recording is uploaded to a Dropbox folder. It can automatically send the file to an AI for a rough cut, generate three potential titles in ChatGPT, and draft a LinkedIn post. This moves the creator from the role of a manual laborer to that of a creative director.
What does not
The biggest failure in the current AI podcasting space is the destruction of metadata. When you run a high-fidelity WAV file through many web-based AI enhancers, they often return a compressed MP3. Even worse, they strip the ID3 tags and the original timestamps. For a professional workflow, this is a deal-breaker. If you lose the 'Date Created' or the 'Original Time Reference' metadata, syncing your multi-track recording later becomes a nightmare.
Then there are the artifacts. AI noise reduction often creates an 'underwater' sound. It happens when the algorithm cannot distinguish between a low-level hum and the subtle resonance of a speaker's voice. It treats the texture of the voice as noise and deletes it. This is why a modular approach is safer. You can apply AI processing in small increments, checking the waveform at each step.
We also have to talk about hallucinations in automated summaries. ChatGPT is an incredible research assistant, but it can confidently misattribute quotes. I have seen it take a point made by the host and credit it to the guest. If you do not have a protocol for correcting these errors, your brand's authority will suffer.
To combat the metadata loss, I use a small Python script within the workflow to verify that the bit depth and sample rate remain consistent after an AI pass.
import soundfile as sf
import os
def check_audio_integrity(original, processed):
orig_info = sf.info(original)
proc_info = sf.info(processed)
if orig_info.samplerate != proc_info.samplerate:
print(f'Warning: Sample rate mismatch! {orig_info.samplerate} vs {proc_info.samplerate}')
if orig_info.subtype != proc_info.subtype:
print(f'Warning: Bit depth changed from {orig_info.subtype} to {proc_info.subtype}')
# Example usage
check_audio_integrity('raw_recording.wav', 'ai_enhanced_output.wav')
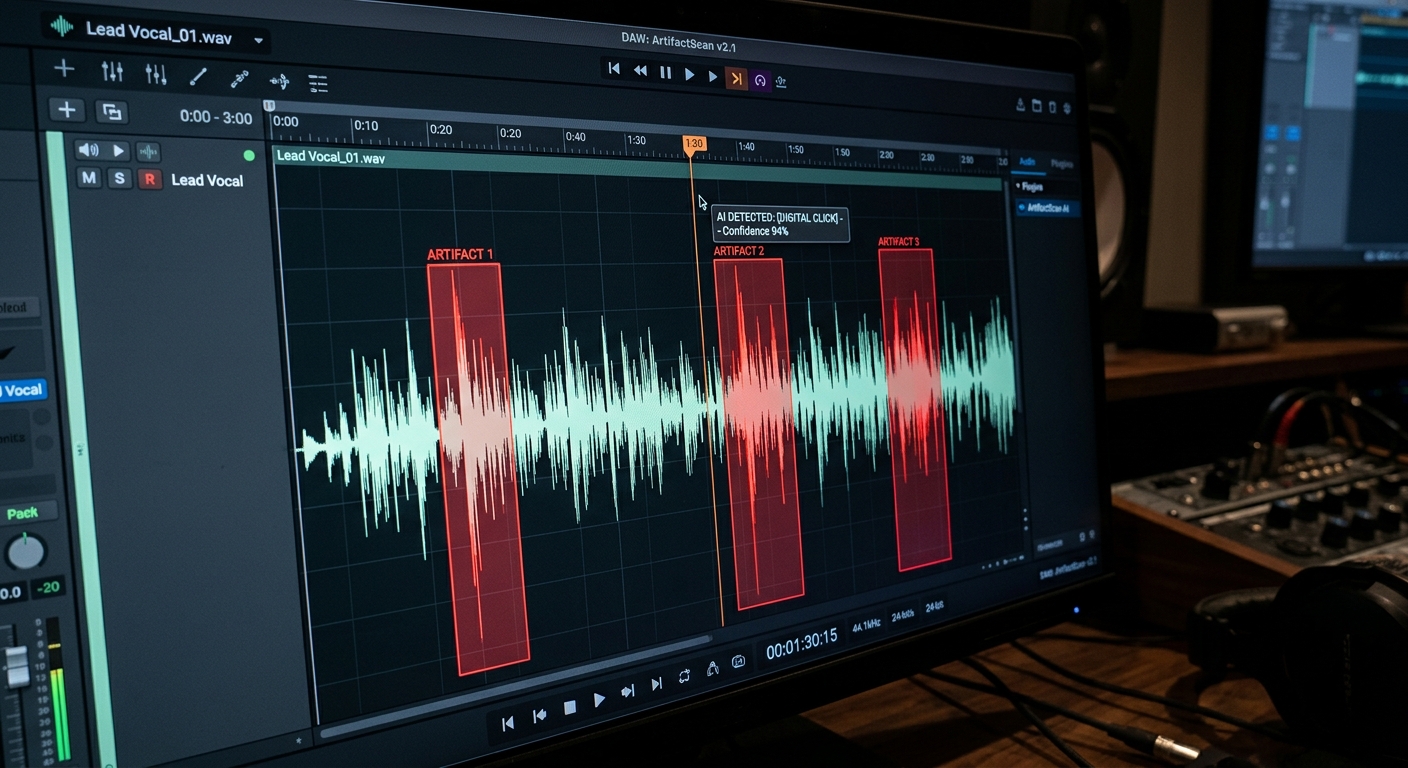
The unsaid tradeoff
There is a legal gray area that most 'best ai tools for podcasters' lists completely ignore. It is the question of copyright and synthetic assets. According to current rulings by the US Copyright Office, works generated entirely by AI without significant human intervention may not be eligible for copyright protection.
If you use an AI tool to generate your intro music or a synthetic voice-over for your ads, you might not actually own that content. This creates a massive risk for commercial feeds. If a competitor uses your AI-generated theme song, your legal standing to sue for infringement is shaky at best.
There is also the ROI calculation. For an independent creator, a suite of premium AI subscriptions can easily top 100 dollars a month.
- ChatGPT Plus: $20/mo
- n8n Cloud: $20/mo
- Descript or similar editor: $30/mo
- Midjourney for cover art: $10/mo
- Specialized hosting with AI features: $25/mo
Total: $105/mo.
If you are producing four episodes a month, that is over 25 dollars per episode just in software overhead. For a hobbyist, that is a steep price. For a professional studio, the time saved (roughly 8 to 10 hours per episode) makes this a bargain. But you have to be honest about which one you are. Are you buying these tools to improve the craft, or are you buying them to avoid the work?
Who should use it
The modular AI workflow is for the podcaster who views their show as an artifact, not just a content stream. It is for the person who wants the efficiency of automation but refuses to give up control over the final sound.
If you are a high-volume creator who needs to churn out daily news bites, an all-in-one platform like Descript is probably your best bet. The friction is low, and the speed is high. But if you are producing narrative non-fiction, deep-dive interviews, or high-fidelity audio dramas, you need the granularity of a modular stack.
By using n8n to bridge your tools, you keep your files in your own environment. You maintain the original fidelity of your recordings. You use ChatGPT to refine your ideas rather than replace them.
This approach requires a bit more technical legwork. You have to understand how to read a waveform. You have to know what a 'hallucination' looks like in a transcript. But the result is a show that sounds like a human made it, supported by the quiet, efficient power of specialized agents. It is the digital equivalent of that heavy volume knob. It gives you the control you need to make something that actually matters.
You can find more resources on building these connections at OpenAI's research blog or by exploring the n8n community workflows. Keeping your production pipeline transparent is the only way to ensure your voice remains truly yours.


