
0.08%. That was the success rate of my first automated support agent before I implemented a formal evaluation loop. I spent $400 on GPT-4 tokens in three days only to realize the bot was hallucinating refund policies that did not exist. Most advice for the solo founder ai stack focuses on which wrapper looks the coolest. That is a fast way to burn your seed money or your personal savings.
If you are building in 2026, you cannot rely on vibes. You need a stack that manages state, measures its own quality, and keeps your unit economics from collapsing into a black hole of API fees.
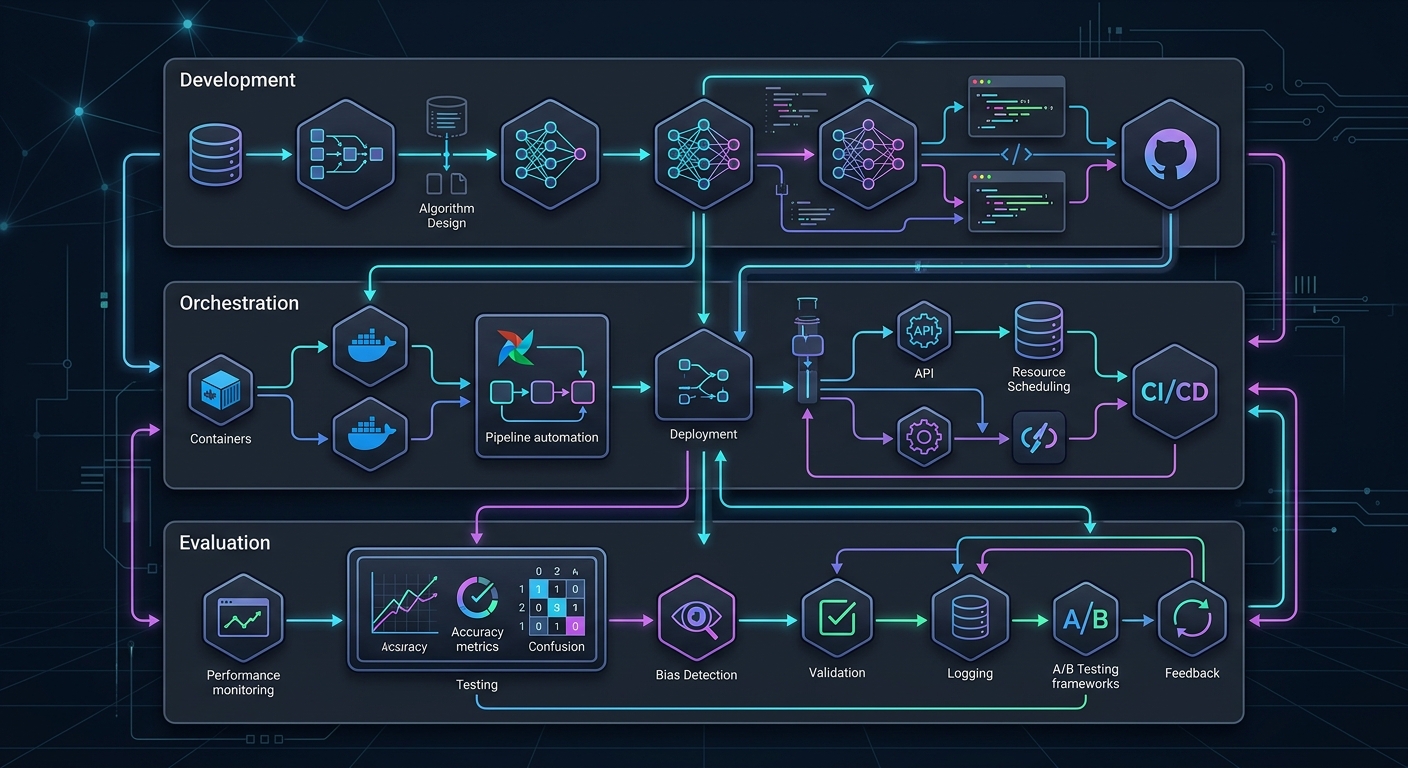
The Solo Founder AI Stack: What it is
The modern solo stack is not a collection of Chrome extensions. It is a three-tier architecture designed for a team of one. It consists of a development layer, an orchestration layer, and an evaluation layer.
At the development layer, you have tools like GitHub Copilot and v0. These are for speed. Copilot handles the boilerplate while v0 generates your UI components. But the real core is the orchestration layer. This is where you use a tool like OpenRouter to access 100+ models through a single API. It prevents vendor lock-in and allows for instant failover if an OpenAI or Anthropic region goes down.
The third layer, which most founders ignore, is the evaluation framework. This is a secondary LLM or a set of deterministic scripts that grades the output of your primary model. Without this, you are just guessing if your product works.
What Works in the Modern AI Pipeline
Speed is the only advantage a solo founder has. Utilizing GitHub Copilot effectively means you are shipping 3x faster than a traditional dev. I have found that using Copilot for writing unit tests specifically for AI edge cases is the highest ROI activity for a solo dev.
Another winner is the unified API approach. Using OpenRouter allows you to swap a $30 per 1M token model for a $0.15 per 1M token model like GPT-4o-mini the moment your prompt logic stabilizes. This directly impacts your payback period. If your CAC is $50 and your margin is thin, those token savings are the difference between a viable business and a hobby.
For UI, v0 has changed how I approach the frontend. Instead of spending six hours on a React component, I describe the state and the data shape. It spits out code that is 90% ready. I then spend the saved time on the data moat.
| Tool Category | Recommended Tool | Why It Wins |
|---|---|---|
| IDE Intelligence | GitHub Copilot | Context-aware autocomplete for proprietary logic. |
| Model Gateway | OpenRouter | Unified billing and model fallback logic. |
| UI Prototyping | v0 | Generates clean Tailwind/Shadcn code from prompts. |
| Voice Synthesis | ElevenLabs | Highest clarity-to-latency ratio in the market. |
| Productivity | Gemini | Deep integration with Google Workspace for document analysis. |
What Does Not Scale (and what breaks)
Most solo founders try to manage AI state in the client or within a basic serverless function. This breaks. LLMs are slow. If your Vercel function times out at 30 seconds but the model takes 35 to generate a complex response, your user sees a 504 error. You paid for the tokens, but the user got nothing. That is a 100% loss on that transaction.
You need an asynchronous architecture. Use a tool like Upstash Redis to manage state and a background job runner like Inngest or BullMQ. The user hits an endpoint, you return a 202 Accepted, and then you poll for the result. This is the only way to build a reliable AI product on a solo budget.
Another failure point is ignoring the EU AI Act and GDPR. If you are processing user data through US-based LLMs, you need a Data Processing Agreement (DPA). Many solo founders think they are too small to be noticed. They are wrong. Automated compliance scanners are getting better. If you want to sell to enterprise customers later, a lack of compliance in your early architecture will kill the deal. You can find the high-level requirements in the EU AI Act summary.
The Unsaid Tradeoff: Reliability vs. Margin
The unsaid tradeoff in the solo founder ai stack is the cost of reliability. To make an AI feature reliable, you often have to run it twice. Once to get the answer, and once to evaluate it. This doubles your token cost.
Here is a simple Python example of an automated evaluation loop you can run inside a background job:
def generate_and_eval(user_prompt):
# Primary generation
response = call_llm(model="gpt-4o", prompt=user_prompt)
# Evaluation prompt
eval_prompt = f"Rate this response for accuracy on a scale of 1-5: {response}"
score = call_llm(model="gpt-4o-mini", prompt=eval_prompt)
if int(score) < 4:
# Log failure and retry or flag for manual review
return retry_logic(user_prompt)
return response
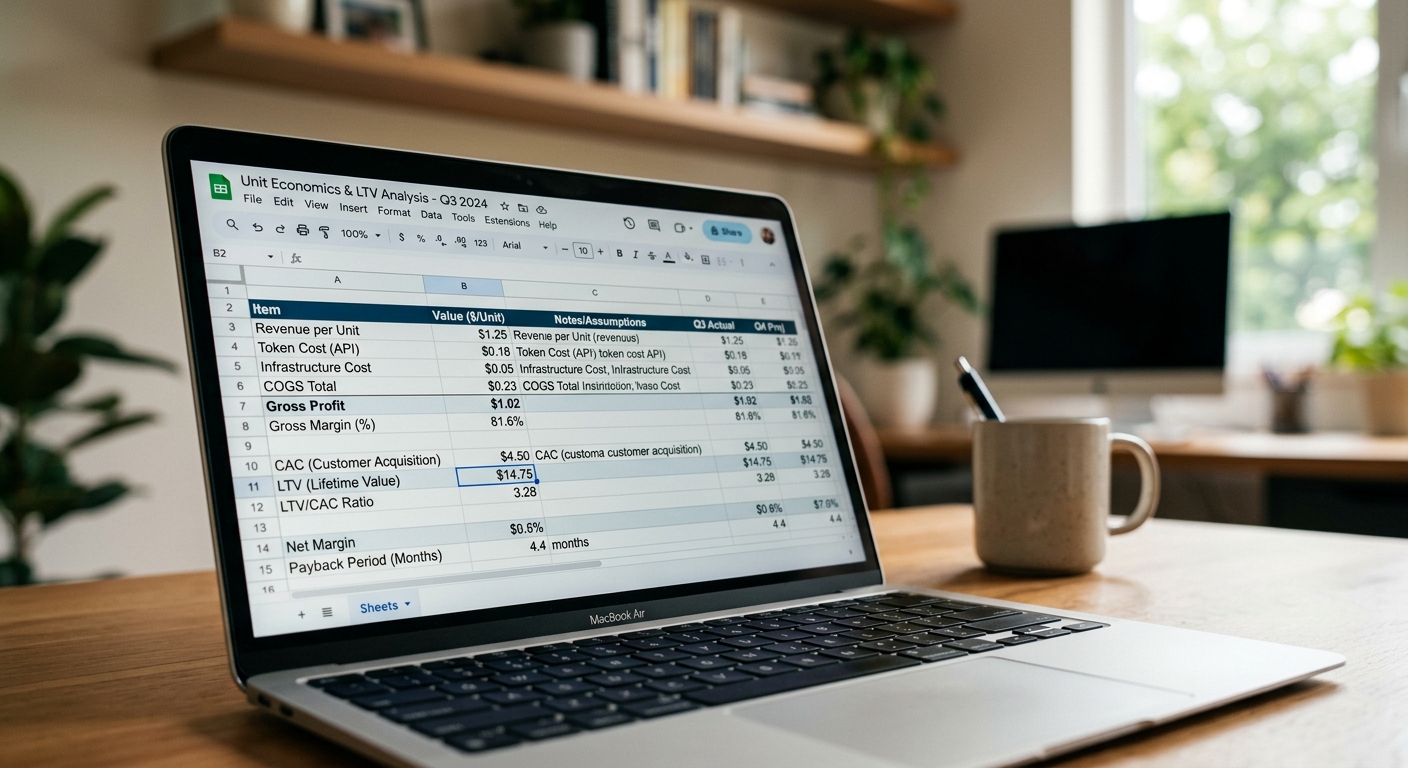
This adds latency and cost. If you are charging $20/month for your SaaS, and a heavy user makes 1,000 requests, your costs could look like this:
- Primary tokens (GPT-4o): $15.00
- Eval tokens (GPT-4o-mini): $0.50
- Hosting/Database: $2.00
- Total Cost: $17.50
Your gross margin is now $2.50. After Stripe fees, you are basically working for free. This is why understanding unit economics is more important than knowing how to write a prompt. You must optimize your stack to move as much work as possible to cheaper models once the evaluation loop proves they are capable.
Who Should Use This Architecture
This stack is for the founder who wants to build a business, not a demo. If you are just playing with APIs, stay with the basic ChatGPT interface. But if you are tracking a retention curve and looking at a six-month payback period, you need this level of technical rigor.
Use this stack if you have a clear plan for a data moat. Commodity LLM APIs are not a moat. Everyone has access to them. Your moat is the proprietary data you collect through user feedback loops and the specific evaluation frameworks you build to ensure your output is better than a generic prompt.
Building a solo AI company is a game of managing ratios. If you can keep your evaluation success rate high while driving your token-to-revenue ratio down, you win. If you want to see how this applies to specific niches, check out my teardown on the best AI tools for email marketing.
Stop shipping vibes. Start shipping numbers. If you cannot measure the accuracy of your AI stack with a script, you do not have a product. You have a prompt.
For more on optimizing your workflow, see my guide on AI for debugging production incidents.


