
// The code the LLM gave us for a 'simple' price calculator
const calculateTotal = (items) => {
return items.reduce((acc, item) => acc + item.price * item.quantity, 0);
};
// It forgot: floating point precision, null checks, and negative inventory.
If you ship code written by a black box without a rigorous validation layer, you are not an engineer. You are a gambler. Two months ago, we decided to speed up our integration pipeline by using LLMs to generate boilerplate parsers for third party API responses. It felt like a win. We were shipping faster than ever. Then the incident happened.
We had a logic regression that bypassed our standard unit tests because the AI generated code handled the 'happy path' perfectly but failed on a specific currency edge case. The result was a four hour rollback and a very uncomfortable post-mortem. Testing AI generated code is not the same as testing human code. Humans make predictable mistakes. AI makes creative, silent, and often catastrophic mistakes.
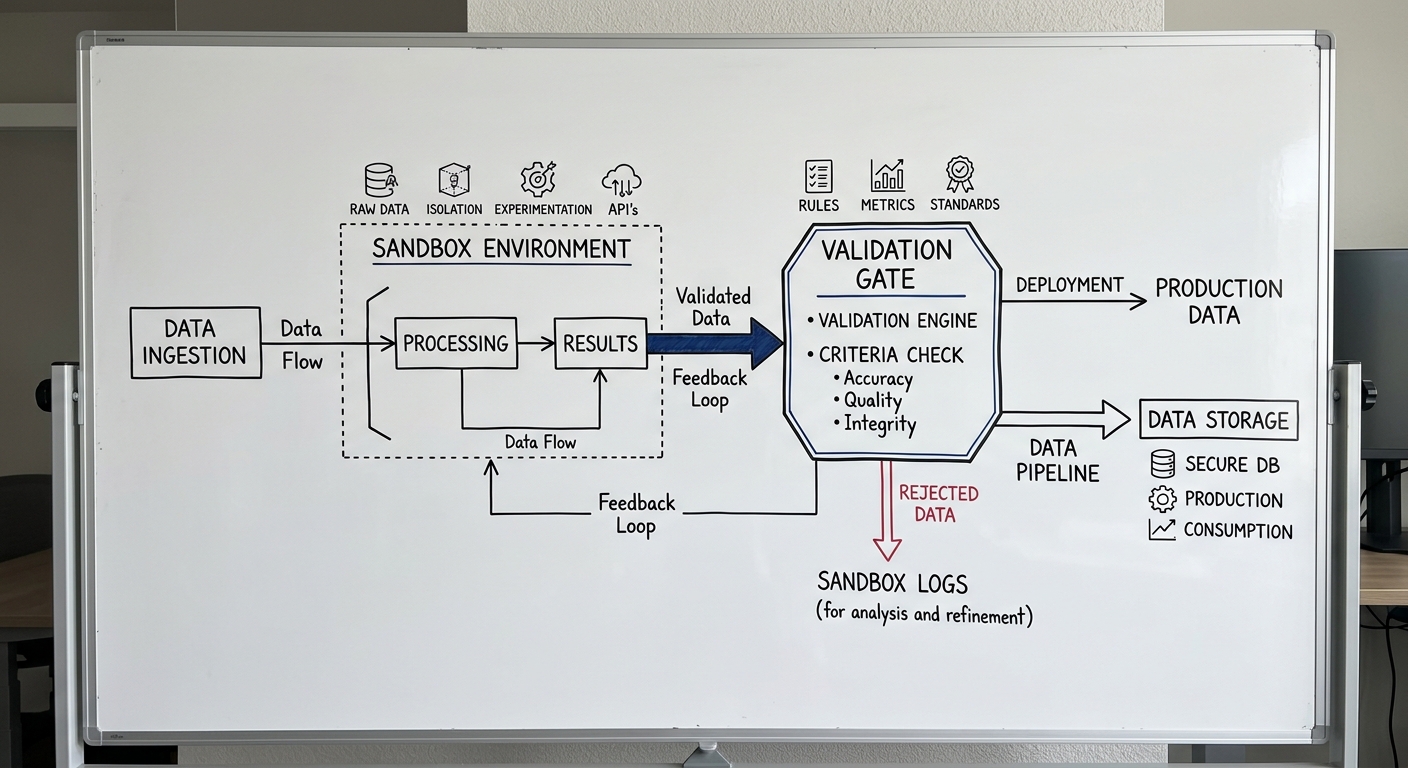
The problem
The core issue with testing AI generated code is the 'illusion of correctness.' When an LLM outputs a function, it usually looks clean. It follows naming conventions. It includes comments. But it lacks the context of your specific infrastructure.
In our case, we were using OpenRouter to bounce between models for the best parsing logic. We assumed that if the code looked good and passed a basic smoke test, it was production ready. This was a mistake. We were treating AI as a senior developer when we should have been treating it like a very fast, very overconfident intern.
We found that 15 percent of the generated parsers contained silent failures. These were not syntax errors. The code would run. But it would fail on edge cases like:
- Floating point math errors in currency conversion.
- Deeply nested null values that only appeared in 1 percent of API calls.
- Improper handling of backpressure when the downstream service throttled us.
The cost of these errors was not just the bugs themselves. It was the engineering time spent on observability and manual log digging. If you are interested in how we handled that side of things, check out my guide on AI for Log Analysis at Scale: A Staff Engineer's Guide.

What we tried first
Our first instinct was to throw more unit tests at the problem. We wrote a script that asked the LLM to generate its own unit tests for the code it just wrote. This was a circular dependency of failure. The LLM simply generated tests that confirmed its own incorrect assumptions. If the parser forgot to handle a null value, the test also forgot to check for a null value.
We also tried manual code reviews. This slowed us down to the point where using AI was no longer a benefit. A staff engineer's time is too expensive to spend forty minutes reviewing a 'five second' AI script. We needed an automated way to verify that the code was safe to ship without a human in the loop for every single line.
What broke
The breaking point happened on a Tuesday morning. We use Selzee to monitor our Shopify store integrations. Suddenly, we saw a spike in 500 errors. A generated parser had failed to account for a 'Compare at price' field being null, which it usually isn't.
The code looked like this:
function formatProduct(data) {
const discount = data.compare_at_price - data.price;
return { ...data, savings: discount };
}
When compare_at_price was null, discount became NaN. Our database rejected the NaN value, the transaction rolled back, and the sync failed. Because this was part of a background job, we did not catch it until the alerts started firing. We had to perform a manual rollback of the service and spend three hours cleaning up corrupted state.
The fix
We realized that deterministic unit tests are not enough for non-deterministic code. We moved to a three tiered testing strategy that focuses on property-based testing and semantic validation.
1. Property-Based Testing
Instead of testing specific inputs, we define properties that must always be true. We use a library called fast-check to generate hundreds of random, messy inputs for every AI generated function.
If the AI generates a price calculator, the property test asserts that:
- The output must always be a positive number.
- The function must not throw an error regardless of the input type.
- The result must be within a sane range (e.g., not a trillion dollars for a t-shirt).
2. Cross-Model Validation (LLM-as-a-Judge)
We use a more capable model, often via Hugging Face or a high end provider, to act as a 'reviewer.' This model does not write the code. It only looks for common security vulnerabilities and logic flaws. It is a separate 'eye' that does not share the original model's bias.
3. Execution Sandboxing
We never run AI code in the main process. We execute it in a restricted environment with strict timeouts. This prevents the AI from accidentally generating an infinite loop or a memory leak that brings down the whole node.
| Testing Method | Human Code | AI Generated Code | Importance |
|---|---|---|---|
| Unit Testing | High | Low | Medium |
| Property Testing | Medium | High | Critical |
| Integration Testing | High | High | High |
| Static Analysis | High | Medium | Low |
Results
Since implementing this 'distrust but verify' workflow, our incident rate for generated code has dropped to nearly zero. We still find bugs, but we find them in the CI pipeline, not in production.
The compute cost for our test suite has increased. Running property-based tests for every PR takes time. However, compared to the cost of a three hour incident and the loss of customer trust, it is a rounding error. We have successfully automated the generation of over 200 data parsers.
We have also found that this approach works well for other AI tasks. For example, if you are using AI for UI copywriting, you can use similar semantic checks to ensure the generated text does not break your layout or violate your brand guidelines.
What we would do differently
If I were starting this over, I would not have started with LLMs for core logic. We should have restricted AI generation to low risk areas like internal tooling or documentation before letting it touch the data sync layer.
I would also have invested in better observability earlier. We were so focused on the 'generation' part of the workflow that we neglected the 'monitoring' part. You can see our current thinking on tool selection in our Midjourney vs DALL-E for Product Design guide, where we talk about choosing the right tool for the right level of risk.
One final takeaway: never assume the LLM understands the library it is using. We saw multiple instances where the AI used deprecated functions or completely hallucinated API methods. Your test suite must be the source of truth, not the AI's confidence. If you cannot test it, do not ship it.


